
30位十年资深工程师

7年技术沉淀

服务1000+行业客户

7D24H极速响应、售后无忧






行业解决方案
多行业多场景多类型产品开发,为企业量身定制专属开发方案

AI人工智能解决方案

即时通讯解决方案

数字一体化管理系统方案

企业研发中心

智慧商城解决方案

本地生活解决方案
智慧社区/园区解决方案

智慧餐饮解决方案

智慧医疗解决方案

智慧医美解决方案

智慧汽配解决方案
智慧管理解决方案
智慧营销解决方案

智慧文旅解决方案
高端网站定制

软件定制开发
我们的优势
匠心打造臻品 实力打造口碑

专业服务-保驾护航

技术可靠-开发无忧

价格-公平普惠

案例-多而全面

售后-保障无忧

周期-时短质优
项目流程
为企业量身定制开发软件操作简单快捷,随时随地访问您需要的实时数据,帮助企业更简捷地达成交易
1
项目启动,成立项目专项小组
2
原型制作、确定周期
3
项目开发,跟踪流程
4
验收合格、部署上线
5
设计稿、源码、操作文档交付
合作案例
甄选1000+开发案例 专业定制各类型软件产品
-

跨境购物平台
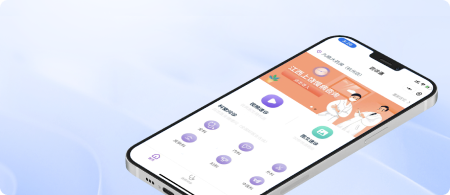
网上问诊-远程医疗、电子处方
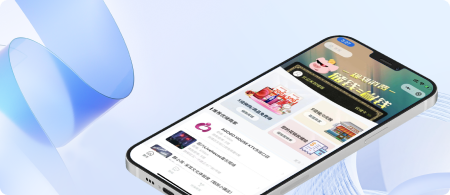
储咖-网上商城兑换平台
-

医疗器械网上商城
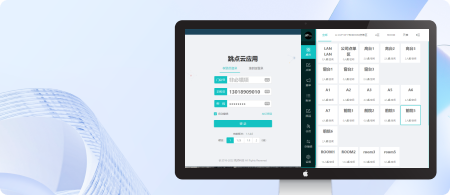
跳点云-智慧店铺管理系统
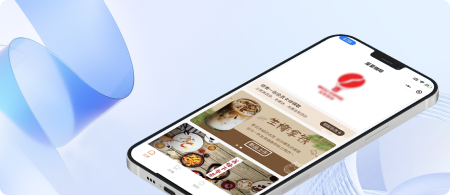
惠生活-实体微店
-

新农特网上商城
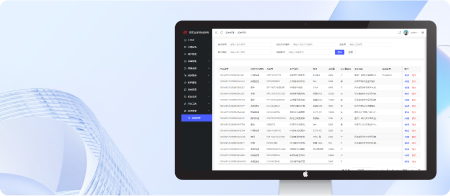
企业ERP管理系统

汽配平台系统
-

社区网上医院
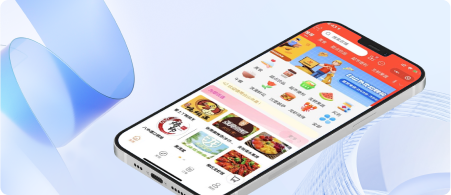
外卖派送平台-本地生活

医院便利店微商城
-
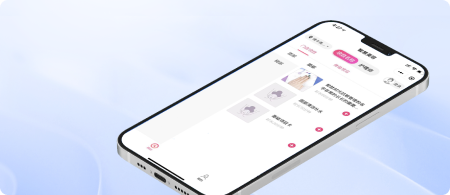
智慧美业预约系统
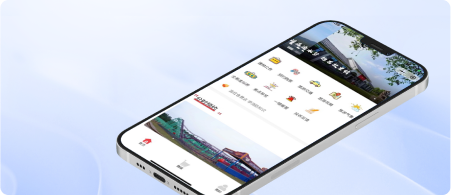
智慧文旅
智慧社区
来自全球1000家企业信赖
服务超过上百家上市公司及大型企业






